













































Use VCE Exam Simulator to open VCE files
Section 4 - Installing, Configuring, and Setting Up a VMware vSphere Solution
Section 5 - Performance-tuning and Optimizing a VMware vSphere Solution
Section 7 - Administrative and Operational Tasks in a VMware vSphere Solution
Troubleshooting is a key skill for anyone in today's technology-driven world. The ability to take a problem, look at it from different angles, break it into smaller pieces, or view the problem in a greater setting is crucial in many areas. From mechanical problems to political barriers, from network failures to development activities, the ability to solve problems quickly is a key component to productivity.
There are several stages to successful troubleshooting, including problem identification, hypothesis, and resolution testing. This chapter will focus on the information gathering and analysis for a vSphere environment, which are crucial to the identification of a problem. Knowing where to find logs and configuration information is a critical step, but understanding how the components function and what different settings do is just as important.
If you are actually troubleshooting a problem, don't forget the classic questions: “What was the last change made?” and “Have you tried rebooting it?”
The following sections will cover some of the higher-level issues around the vCenter Server and ESXi hosts, such as services, overall monitoring, and health.
Some of the tools to use when troubleshooting vCenter include the web client (https://<vCenter IP or FQDN>/vsphere-client), the appliance UI (https://<vCenter IP or FQDN>:5480) for VCSA, and the Windows management tools for the installed version of vCenter. The VCSA has an additional tool, vimtop, which is available from the command line.
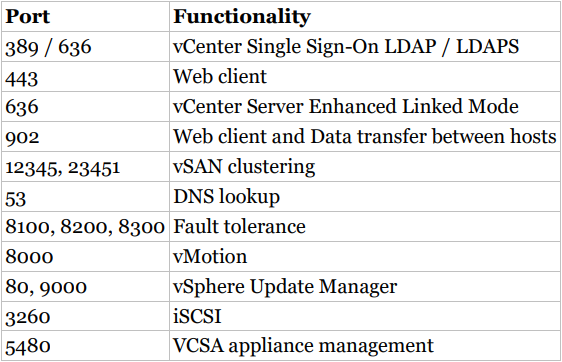
If you cannot connect to the appliance or web client, or if your hosts cannot communicate with vSphere, check for network connectivity issues or a firewall between the components blocking the required ports. VMware has an extensive list of the ports needed in the vSphere documentation under “Incoming and Outgoing Firewall Ports for ESXi Hosts” and “Required Ports for vCenter Server and Platform Services Controller.” A brief list of these ports is contained in Table 8.1.
The vCenter server has several key services that are always required and optional services for functionality such as Auto Deploy. You can check the status of vCenter and its services from the System Configuration page for the node (see Figure 8.1).
Or get a list of services and their status by using the Services menu as shown in Figure 8.2.
The full list of services includes the ability to start, stop, and restart services plus the ability to change the startup settings of each service. This is where you go to “enable” Auto Deploy and ImageBuilder by setting the services to always start. Note that if an upgrade of vCenter fails due to Tomcat (the VCSA web service) not stopping, the VMware Troubleshooting documentation suggests setting the VMware vCenter Management Webservices and VMware VirtualCenter Server services to manual and then rebooting the server.
One common source of issues for vCenter servers is the database holding the events and statistics. To avoid running the volume holding the database out of space, you can monitor it using the df -h command from the VCSA appliance or using the Windows Explorer or Disk Management tools if vCenter is installed on a Windows server.
To reduce the space used by the database, you can adjust the statistics levels kept as well as how long the levels are kept. The statistics settings are available in the Configure tab of the vCenter object ( Figure 8.3 ). When you are changing the settings, the estimated maximum size of the database is displayed on the bottom right-but you need to set the host and VMs numbers for the best accuracy. When you're setting the levels, Level 1 saves the fewest number of statistics and thus takes up the least space, and Level 4 is for debugging and saves all statistics.
You can also adjust the time tasks and events will be retained in the database under the Database options of vCenter Server Settings; however, the Task Cleanup and Event Cleanup options must be selected before the time settings will be honored (Figure 8.4).
Additional statistics are available for the VCSA appliance in the form of a command-line tool called vimtop, which the VMware documentation refers to as a “plug-in.” Very similar in look to the esxtop utility, vimtop will display the running tasks with their CPU and memory usage as shown in Figure 8.5.
Useful keystrokes for vimtop include the following:
You can start vimtop with specific configuration files using the -c parameter. The default configuration file is located at /root/vimtop/vimtop.xml. Other command-line options include -n to set the number of iterations and -p or -d to set the update period in seconds.
If you are using encryption in your environment, you may be deploying KMS servers to manage the keys. If you encounter issues, be aware that round-trip latency between vSAN hosts and the KMS server cannot exceed 1 second. If you are using large SSL certificates (greater than 2,048 bits) or have network latency between the KMS and hosts, you could encounter problems.
You also need to ensure that vCenter can access the KMS server or cluster at all times to ensure that VMs can been unlocked when requested by hosts. If you encounter a key/key ID mismatch on the KMS server, you can retrieve the key ID using the Managed Object Browser at VirtualMachine.config.keyId.keyId. Having the KMS administrator reactivate the key associated with that ID should resolve the issue.
Connectivity to a vCenter server and between vSphere components (PSC, hosts, postgres database) depends on correct authentication of the certificates used to secure the communications. A default install of vSphere will generate certificates using the VMware Certificate Authority daemon running on vCenter, but for production use these should be replaced with certificates from your corporate authority or a commercial CA.
There are a few areas where you might run into issues after replacing your certificates.
General connectivity Existing connections might remain open and continue to use the old certificate after replacement. You can shut the network interfaces or restart the vCenter Server service to ensure that all connections are reset.
Database connectivity If vCenter can't connect to the database, use the vpxd -p {password} command to reset the password, which will re-encrypt it with the new certificate.
Host connectivity If hosts cannot connect to the vCenter server after certificate updates, disconnect and reconnect them from vCenter. The official documentation suggests you do this from the ESXi hosts, but you can only disconnect-and that's not permanent, as rebooting the host should reconnect it.
HA enablement You may encounter an error when enabling HA that “vSphere HA cannot be configured on this host because its SSL thumbprint has not been verified.” Again, disconnecting and reconnecting the host from vCenter should resolve this issue.
One of the first steps for troubleshooting a new problem is examining the log files. Common log files are described in the following paragraph, but note that you will need to check the specific host or machine having the issues for the correct log file. Troubleshooting using log files also depends on having the time accurate (and synchronized) on the machines in your environment. Troubleshooting connectivity or security issues between multiple machines is made much easier when you can match the log entries to the second and compare entries between the logs.
Installation logs for the installed version of Windows can be found at %PROGRAMDATA%VMwarevCenterServerlogs as well as the %temp% directory on the Windows server. In the temp directory, look for vminst.log, pkgmgr.log, pkgmgr-comp-msi.log, and vim-vcs-msi.log. The VCSA installer has a log file at C:UsersAdministratorAppDataLocalVMwareCIPvcsaInstaller; however, if the installer encounters a problem, it should prompt you to create a zip file with the relevant logs for troubleshooting.
If you encounter problems with the web client, on the installed version you can check the same %PROGRAMDATA%VMwarevCenterServerlogs directory, or for VCSA look in /var/log/vmware/vsphere-client/logs. The main log file for the vSphere web client is vsphere_client_virgo.log.
A comprehensive list of logs is available in the vSphere Troubleshooting guide, but I'll list some of the key ones here. For an installed version of Windows, the logs are found in the directories under %PROGRAMDATA%VMwarevCenterServerlogs, and for VCSA they are in directories under /var/log/vmware/. I already mentioned installation and web client logs, but also be aware of these:
vpxd-main vCenter Server log
CM-VMware Component Manager
FirstBoot-first boot logs
EAM-ESX Agent Manager
InvSvc-Inventory Service
vPostgres-Postgres database service
Vmcad-VMware Certificate Authority
These are directories containing the relevant logs and will be all lowercase on the VCSA appliance. The vpxd log is the first one to check for general vCenter issue, including client and web services connectivity, internal tasks and events, and vpxa communications (the vCenter Server Agent running on managed hosts).
You can use the VCSA appliance management page (VAMI) to create a support bundle as shown in Figure 8.6 or execute vc-support.sh from the command line.
While the button in the VAMI will automatically download the support bundle to your browser, you will need to retrieve it via SCP from the VCSA appliance if you use the vc-support.sh script as shown in Figure 8.7
You can also view and download the vCenter logs using the vSphere client as shown in Figure 8.8. While you can only view the vpxd logs using the client, you can download all of them. This method can also download ESXi log files.
EXERCISE 8.1 Export ESXi and vCenter log files.
From the web client, select your vCenter server and open the System Logs view from the Monitor tab:
Click Export System Logs.
Select your ESXi hosts and select Include vCenter Server And vSphere Web Client Logs.
Select Password For Encrypted Core Dumps and enter a password.
Click Finish.
Select a directory and accept the default name for the log file.
Wait for the log files to download.
Extract the .tar file from one of the ESXi .tgz files.
Extract the log files from the .tar file and locate the vmkernel.log file in the var/run/log directory.
VMware Skyline
VMware has a little-known tool called Skyline that is included with every production support contract. Skyline is a proactive support product that collects, aggregates, and analyzes VMware product logs and telemetry information.
Skyline deploys as an appliance and connects to vCenter servers and NSX Manager to pull configurations, performance data, changes, and events, which are then sent to VMware for analysis.
Using data collected from customers around the world, Skyline can anticipate and predict issues in your environment.
If a problem is encountered, Skyline can be used to forward relevant logs to VMware-and associate them with your support ticket during uploading
If you have a valid support contract, you should be looking into adding Skyline to your environment if only for the ease of sending logs to VMware if needed.
When you connect ESXi hosts to a vCenter server, a local user (vpxuser) is created and an agent service (vpxa) is configured and started, as shown in Figure 8.9. The vCenter host will leverage the vpxa service and vpxuser credentials when managing the host.
There are several issues you could experience regarding hosts. For the most basic of troubleshooting (after making sure everything is powered on and running), make sure you can ping the FQDN and IP address from the vCenter server to the host and from the host to the vCenter server. If you can't resolve the FQDNs, make sure the correct DNS server IP is in use and check the DNS servers. If there is no IP connectivity, you will need to look at the network hardware and work with the network team to test connectivity and things such as proper VLAN tagging.
If you encounter a “not responding” issue (see Figure 8.10) and the host is up and you have IP connectivity, there are a few steps to take to resolve it. First, as shown back in Figure 8.9, you can restart the vpxa service. You can also work with your network team to ensure that there is not a firewall between the hosts and vCenter blocking port 902; however, this would need to be a recent change as it would have prevented adding the host to vCenter in the first place.
The final step for many issues (such as connectivity problems after replacing certificates) is often disconnecting and reconnecting the host from vCenter as shown in Figure 8.11.
If High Availability is enabled on the host, there is an additional agent service (vmware-fdm) started on each host that manages elections and HA when vCenter is not available. If problems arise with HA, they are usually classified in one of these states:
Unreachable State Host communication error or HA configuration is off. If the host is communicating with vCenter, reconfigure HA (Figure 8.12).
Uninitialized State Host might have lost access to datastores; HA is misconfigured or stopped. If the host can see all datastores properly, reconfigure HA (Figure 8.12).
Initialization Error State Host communication error, out of disk space, or host needs to reboot. If the host is communicating, free up disk space or reboot host as needed.
Uninitialization Error State Usually host communication error. Resolve and reconfigure HA (Figure 8.12).
Host Failed State Usually host communication error or lost access to datastores.
Network Partitioned State Host communication error where the Master HA host can't access another host by network but can exchange heartbeats-often caused by physical network changes.
Network Isolated State Host communication error where the host can't access the isolation addresses or any other hosts in the cluster. Usually a physical network problem.
Coupled with High Availability is the Fault Tolerance option for virtual machines. VMware's FT technology requires low-latency network connectivity for proper operation. You should ensure that you have a 10 Gbps link between hosts and a dedicated VLAN and VMkernel adapter for Fault Tolerance, and you should work with the network team to ensure the lowest latency possible between the hosts.
Hair-pinning the traffic to a physical firewall or use of a bridge firewall or any other service that examines packets should be disabled for the Fault Tolerant network. The network does not need to be routed or extended beyond the hosts participating in Fault Tolerance. You should also ensure that all of your hosts' firmware and drivers are upto-date and review any documentation from your vendor regarding VMware and Fault Tolerance best practices.
If you have several VMs with FT enabled, make sure you monitor the environment to ensure that one host isn't swamped with multiple FTenabled machines. Since DRS won't migrate FT-enabled machines, you will need to balance them yourself-and periodically check, as power-cycling the virtual machines can change the location of the FT copy, as can activities like disabling FT for updates or other maintenance.
You can monitor your ESXi host using the host UI, from vCenter, or from the command line using esxtop (see Figure 8.13, Figure 8.14, and Figure 8.15).
The host UI is great for standalone hosts, or to check on hosts that are having issues connecting to vCenter. The vSphere web client is the preferred method as it has more information than the host client-and has all of the configuration settings for the host. The command-line tool esxtop is great for granular examination and is the most detailed in the areas it covers, but is often too detailed to start troubleshooting with since it doesn't display things like recent tasks or events.
All three of these tools can report on performance, but the vSphere client is best for historical information, trends, readability, and export capabilities (image or CSV). The esxtop tool is best for fine detail and scheduling data captures.
The VCP exam should not have significant questions on the esxtop tool, but here are some things you should know:
There are two versions, esxtop for your local host and resxtop to capture data from remote hosts. While esxtop is installed with any host deployed, resxtop is available with the vSphere CLI package or the vSphere Management Assistant (vMA) virtual machine.
You can use esxtop in interactive or batch mode. Simply running esxtop starts it in interactive mode where you can use keyboard keys to change the display panel:
In batch mode, you call esxtop using the default configuration or a customized config file with parameters to set how many sets of data to capture and how long to wait between captures. Note that you need to start esxtop and use an uppercase W to save a configuration file before using esxtop in batch mode.
To start esxtop in batch mode, the minimum command line is esxtop > filename.csv, capture for the default 5 second intervals, and redirect the output to a CSV file in the directory you are in. Realistically you will want to specify -n x to set a specific number of intervals to capture or the utility will simply continue to run until it is manually stopped or the disk is out of space. For resxtop, you will also need -server and -username (you will be prompted for the password).
EXERCISE 8.2 View esxtop stats.
Connect to an ESXi host using SSH.
Start esxtop.
Press u to switch to disk device view.
Press f to show the column chooser.
Press F and G to remove the QSTATS and IOSTATS information.
Press Enter to return to the stats screen and view the DAVG, KAVG, GAVG, and QAVG stats for your devices.
EXERCISE 8.3 View vimtop stats.
Connect to a VCSA appliance using SSH. Disabling “auto wrap” in your SSH client may result in a better view for vimtop.
Start the shell.
Enter vimtop to start the utility
Press p to pause the display. Use the arrow keys to scroll and view the processes.
Press p to resume.
Press o to view the network statistics.
With a vSphere environment, troubleshooting network and storage issues usually involves working with the physical hardware supplying the services. Even troubleshooting vSAN often involves the network team. Specific hardware troubleshooting steps should come from your vendors-and checking with them for documentation including design guides and white papers is always a good idea.
In the following sections, we will look at different storage and networking issues you might encounter and show you how to locate information that should help troubleshoot any issues with the hardware vendors.
There are several storage technologies available to vSphere, including SAN (Fibre Channel and iSCSI), vSAN, and virtual volumes (VVols). All of these except for Fibre Channel leverage the TCP/IP networking stack and physical networking components, so make sure you are considering those areas when troubleshooting.
Storage area networks (SANs) using Fibre Channel or iSCSI share many similar processes. I'll point out if steps are only for one technology or the other.
If you cannot see the LUNs you are expecting on a host, start by narrowing the problem down. Can you see any LUNs? If you can see some LUNs, do they have anything in common? You might need to work with the storage team to identify any similarities, such as all available LUNs are on one SAN or one storage processor (SP).
If you cannot see any LUNs at all on a host, you should be looking for a connectivity problem, either physical (bad, disconnected cable), digital (bad, wrong drivers) or logical (improper zoning for Fibre Channel devices, mapping, or security for iSCSI). Check the other hosts-do any of them see the LUNs? If so, what is different?
The zoning or mapping issues need to be addressed and worked on from the storage side. You can help by providing the IP address for the VMkernel port in use by iSCSI and the iSCSI name, as shown in Figure 8.16 .
For Fibre Channel, provide the storage administrator with the worldwide node and worldwide port IDs used by the host so they can easily identify it from their end.
If you are using iSCSI with CHAP authentication, make sure no changes have been made to the password or CHAP requirements.
You can also check the MASK_PATH plug-in, as shown in Figure 8.17 using the esxcli storage core claimrule list command on the host to ensure that no LUNs have been masked at the host, preventing them from being used.
Note that the MASK_PATHs shown in Figure 8.17 are created by default and likely exist in your environment.
If you experience problems with a VMFS datastore, including outages, files not being available, or error messages related to corruption, you can check the consistency of the datastore using the VOMA commandline tool. Note that if VOMA reports errors, you should contact support for assistance resolving them.
Before using VOMA, power off any VMs on the datastore.
VOMA requires the device name and partition for the datastore, so step one is identifying the device name using either the web client or the esxcli command as shown in Figure 8.18.
Once you have that, you can run VOMA using the parameters -m vmfs -f check and -d with the device and partition, as shown in Figure 8.19.
The -m parameter can be used to check VMFS (version 3, 5, and 6), or you can include the lvm parameter to have it check the logical volume backing the VMFS datastore.
After any changes, be sure to rescan your HBAs (see Chapter 4, “Storage in vSphere,” for more information).
Storage performance issues can come from several areas-including the physical network if Fibre Channel is not in use. Common problem areas are SCSI reservations, path thrashing, and LUN queue depth.
ESXi hosts can use SCSI reservations for file or metadata locks in VMFS. As SCSI reservations lock the LUN, an overabundance of them can cause performance issues. Changing the VMFS datastore, creating VMs or templates, powering on or migrating VMs, or using thinprovisioned disks (including snapshots) can all cause a host to issue a SCSI reservation.
One way to identify SCSI reservation issues is to examine the /var/log/vmkernel.log file on your host and look for “RESERVATION CONFLICT” messages.
To combat this, you can reduce the use of snapshots and the number of VMs per datastore. You can also work with your processes to limit how many datastore-impacting operations run at one time. You should also ensure that your firmware, BIOS, and drivers are up-to-date.
Path thrashing occurs when a LUN is being serviced by multiple storage processors and the storage processors are “fighting” over the LUN. Usually this occurs on active-passive LUNs when either the SAN or the hosts are misconfigured. Ensure that all hosts are configured to access the SAN and LUN in the same way and that all LUNs are set to use the Most Recently Used (MRU) path selection policy.
The LUN queue depth issue arises when a ESXi host queues storage requests due to the limits of the LUN queue depth setting. Note that while the SCSI drivers should have a configurable LUN queue depth setting, you should only make changes in conjunction with the vendor's support team.
You can adjust the queue depth using the esxcli command (note that this must be run on each host affected) as follows:
esxcli system module parameters set -p parameter=value -m module
For this command, module is the name of the SCSI driver.
Another way to examine SAN performance issues is to use the esxtop command. Once it's started, use the u command to switch to device view, shown in Figure 8.20. Note that here I have used the f command to remove many of the default columns to improve readability.
Here you can see the values for DAVG (device), KAVG (kernel), GAVG (guest), and QAVG (queue), which are the average (AVG) response times at different points in the SCSI request cycle.
DAVG is the time for a command to leave the host and return from the array. This should be the longest value listed. This value can be tracked over time or compared to similar hosts. Generally speaking, this value should be less than 10 ms for top performance, but this could vary depending on your storage, current usage, and system design.
KAVG is the time it takes the VMkernel to process a request, and QAVG is the time a request spends in the HBA driver. These should always be very short (<1 ms).
GAVG is the sum of the other three times and is the time the request is waiting for storage requests to process.
Storage DRS and Storage I/O control are useful tools, but there are some caveats and areas to examine if problems arise when using them.
For Storage DRS, be aware it can't be enabled for templates, ISO files, virtual machine swap files, independent disks, or virtual machines that have operations such as Storage vMotion currently affecting them. Storage DRS also cannot be used with Fault-Tolerant enabled virtual machines.
If you are trying to perform maintenance on a datastore but the datastore doesn't complete entering maintenance mode, ensure that any disks remaining on the datastore have Storage DRS enabled and are configured such that they can be moved.
If you cannot enable Storage DRS on a datastore, make sure the datastore isn't shared between datacenters and that all connected hosts are compatible and do not have Storage I/O control running.
For Storage I/O control issues, make sure all hosts connected to the datastore are compatible, support Storage I/O control, and have the appropriate license. If you see an “Unmanaged workload is detected on the datastore” message, you should check with the storage admin as Storage I/O is detecting activity on the datastore it cannot account for.
For more information on Storage DRS and Storage I/O control, see Chapter 4.
The network is a key component for a vSphere infrastructure since without it you can't manage a host or access network-driven storage (NFS, vSAN, iSCSI) and virtual machines can't communicate. Network issues usually revolve around vSphere configuration, hardware configuration, and hardware problems.
While hardware problems are outside the scope of this book, you can identify disconnected physical network interface cards (pNIC) using the web client, as shown in Figure 8.21. Also in Figure 8.21, you can see the observed network range(s) per adapter.
The observed traffic field is useful to determine what VLANs are configured for each pNIC, although it requires listening for broadcast packets. Networks with no or little traffic, or specialized traffic such as storage networks, might not have broadcast packets and might not appear in the list.
Another useful tool for troubleshooting network issues is enabling CDP or LLDP on distributed switches. This will report information from the physical switches (if configured), including port ID and switch name, and is key to ensuring that your configuration matches the physical configuration. See Chapter 3, “Networking in vSphere,” for more information.
Finally, standard and distributed switches can be configured for network failure detection or beacon probing, as shown in Figure 8.22.
Network failure detection (the default setting) will stop vSphere from using a network adapter that is not connected to a network, while beacon probing will send packets down each path to determine if an adapter can reach the proper network. This prevents traffic from being sent down a network adapter that is plugged into the wrong port on a switch. Note that beacon probing requires at least three NICs to function properly. With only two NICs, if either had a problem, neither would be used since the host would not know which of the NICs had a problem.
Verifying that your network connection is correct is a key step in troubleshooting issues. This is compounded if you are using standard switches since the configuration needs to be set on each host.
One useful tool for this is the network view in the web client, where you can quickly see the port groups on standard switches along with the number of hosts using each port group (listed under the Networks tab in the GUI) as shown in Figure 8.23.
You can also select each network and view the virtual machines (or templates) connected to it (Figure 8.24).
To confirm the proper configuration, you need to access the settings of each network-and for standard switches you need to do this on each host. While it is possible to have different configurations on each host (VLANs used, failover), it is far easier to manage an environment where everything is configured the same way. If your environment requires differences (such as different VLAN tags for the same network on different hosts), make sure you have that documented. There is no place in the vSphere settings to make notes on configuration differences.
VLANs are a common area of concern, since an improper tag will prevent the traffic from being placed on the correct network-but your “connectivity” indicators such as green lights on the physical ports will look fine. A quick troubleshooting step is to place virtual machines on the same network/port group on the same host. If VMs can talk on the same host but can't talk when on different hosts, then you have a physical network issue, which could certainly be a VLAN tag mismatch.
Along with VLANs, the more specialized PVLANs can cause problems when not configured properly. Two VMs on the same network that are on an isolated PVLAN won't be able to talk, nor can they talk if they are on different community PVLANs. With PVLANs you also have another layer to configure on the physical switches, setting the PVLAN type properly for each network.
Again, moving VMs that should be able to talk together onto the same host will quickly isolate whether the issue is a physical network one.
Finally, network latency or performance issues can be caused by misconfigurations such as these:
You should also verify that your system BIOS, network card firmware, and drivers are up-to-date.
If no traffic is passing at all, make sure you check the VM's network connectivity and port blocking at the VM and port group levels.
When updating your vSphere environment, the key first step is to do the upgrades in order, from the “top” down. VMware KB article 2147289 has all the VMware products in a table, in order, but in general terms you want to go as follows:
Upgrading your host before your vCenter server is a common mistake. Also, make sure you have backed up anything you are upgrading, just in case.
After ensuring that you are backed up and upgrading in the correct order, there are some areas in which you might run into trouble. For instance, vCenter occasionally has issues stopping the Tomcat web service during an upgrade. If you see an error message about Tomcat, try stopping the service manually or rebooting the host.
As mentioned earlier, in the section “vCenter Connectivity and Services” regarding replacing SSL certificates, if your hosts can't connect to vCenter after an upgrade, try disconnect/connect.
For other upgrade issues you can check the log files at C:ProgramDataVMwarevCenterServerlogs and in the %TEMP% directory-specifically the vc-install.txt, vminst.log, pkgmgr.log, pkgmgr-comp-msi.log, and vim-vcs-msi.log files.
If you are using Update Manager to apply updates, there is a log file (vmware-vum-server-log4cpp.log) that will include errors returned by the precheck script that runs before updates are performed.
Virtual machines running on ESXi hosts need some occasional care and feeding, with both proactive and reactive processes. One good tool for both proactive and reactive monitoring of virtual machines is the performance view from the host (Figure 8.25).
Note that performance charts are available from the cluster, host resource pool, and individual virtual machine level. The host view is the most practical as it shows the virtual machines whose performance is directly impacting each other, but all of the views have their uses. Note that the CPU and memory used is from the point of view of the host and won't necessarily match from the guest point of view.
Contention managing tools such as shares, limits, reservations, and memory swapping can make the guest results considerably different.
One of the more useful counters is the CPU Ready value, available in the Advanced CPU charts (Figure 8.26).
Figure 8.27 shows the same host using the esxtop tool. Note the %RDY, which is the CPU ready as a percentage for each virtual machine.
This ms value from Figure 8.26 shows the time guest CPUs were waiting to run. This is often expressed as a percentage, which is the percent of time spent waiting over the sample period. A consistently high CPU Ready time (over 5%) implies the host is being overloaded and virtual machines should be moved off it.
You can use the performance charts (and esxtop) to view the memory usage also for the cluster, host resource pool, and individual virtual machine level. Remember that ballooning is taking memory back from virtual machines; this is an indication that you have overallocated RAM but isn't necessarily a problem. See Figure 8.28 for an example of a host using ballooning.
Swap, on the other hand, is always a problem as that indicates overallocated RAM. Virtual machines are actively contending for physical memory and the host is writing some guest RAM pages to a storage file. This usually results in significant performance penalties to the VM that is experiencing the swapped memory.
The performance charts are available as Overview with set values selected and Advanced charts where you can pick the values to display, as shown in Figure 8.29. Advanced charts can also be saved as image files or CSV files.
Issues encountered when using the High Availability and Dynamic Resource Scheduling features of vSphere can take a variety of forms. For starters, make sure you have the correct license version to enable the features. While vCenter Standard includes HA, you need Enterprise Plus to enable DRS and proactive HA. And only HA is included with the Essentials Plus level, but not even HA is included with Essentials.
Once the licensing is in place, you need to meet the prerequisites to enable HA or DRS (see Chapter 10, “Ensuring High Availability for vSphere Clusters and the VCSA,” for more information). Once they are enabled, some of the situations you might run into include running out of resources, heartbeat datastore availability, and unprotected virtual machines.
One of the first places to go for issue troubleshooting is the Issues view of the Monitor tab, as shown in Figure 8.30 (note that most objects in vSphere have this view available).
In this case, HA is reporting that it cannot satisfy the failover requirements. This would normally be the case if admission control was disabled, but it could happen if hosts are unavailable in the cluster, from being in a non-running state or in maintenance mode or from an HA agent problem or a connectivity problem.
Similarly, you could be prevented from powering on virtual machines in a cluster due to admissions control being set and either being set too high (large slots for small virtual machines or excessive resource percentage) or hosts not being available. If all the proper hosts are available, you can check the slot size using the summary section of the vSphere HA view for the cluster (Figure 8.31).
If you are not using a fixed slot size, powering on VMs with large reservations or enlarging the reservations on existing machines can set this high enough to block new VMs from powering on due to a reduced number of slots. For more information, see Chapter 10.
Heartbeat datastores could become an issue for your HA cluster if there are storage changes in your environment and you had manually selected datastores, or if there are no available shared datastores. Note that vSphere doesn't always use the datastores you manually select if you select more than two, if the ones you select are not shared, or if a datastore becomes unavailable.
This chapter has covered troubleshooting a vSphere environment. Key to troubleshooting is understanding how the product works and how your environment is configured. Past that, there are a few ways to pull log files and several tools that can be used to examine the current state of the environment.
Since understanding the functionality and settings of different components is crucial to troubleshooting, the other chapters in this book are important for referencing. Knowing that virtual machine reservations affect slot size, which affects admission control, which affects high availability and can prevent you from powering on new virtual machines, can be critical to troubleshooting a VM that won't power on.
Some of the best tools for troubleshooting are the same ones used for monitoring the day-to-day operations, such as the Performance tab. Using those tools periodically will keep you aware of the baseline performance of your environment and could give you a heads-up on potential problems. Other tools such as esxtop are usually only used during troubleshooting due to the depth of information they produce.
Finally, troubleshooting often involves vendors and other teams such as the networking and storage teams. Be sure you involve those other teams in your troubleshooting process and be prepared to discuss how vSphere interacts with those systems.
Know common network ports used by vSphere. Especially 902 (ESXi connectivity), 8000 (vMotion), and 5480 (appliance management), but be familiar with the others listed also.
Be familiar with the most common vCenter services. Know vpxd, Auto Deploy, ImageBuilder, and Tomcat, where to start/stop them, and why.
Understand the different vCenter database settings. Especially the ones controlling the size of the database (performance counters) and where to change the settings.
Know the difference between vimtop, esxtop, and resxtop. The vimtop utility is available on the VCSA appliance and works with vCenter. esxtop is on each ESXi host and shows local stats, and resxtop is on the vMA management appliance or the vSphere CLI download and looks up performance stats on remote ESXi hosts.
Know how SSL certificates are replaced and the more common troubleshooting tasks around them . Knowing the proper steps to replace them is key, but reconnecting hosts is a common resolution for certificate issues.
Know the most common log files and how to access them. Especially vpxd and vmkernel. Make sure you have viewed files in the GUI and exported from vCenter and ESXi hosts.
Know the ESXi agents vpxa and vmware-fdm. The vpxa agent communicates with vCenter and vmware-fdm managed HA (if HA is configured).
Know the basics of storage and network troubleshooting. Much of storage revolves around networking, so be able to pinpoint a network issue vs. storage and then drill down on the network. Be familiar with CDP and LLDP and identifying network and storage configuration issues.
Know CPU Ready and how to pull performance reports. Understand the uses of the performance charts vs. esxtop and what a high CPU ready state looks like.
What tools can be used to create CSV files of virtual machine performance data? (Choose two.)
What log file is considered the main vCenter log file?
Where can you download ESXi host logs? (Choose two.)
Where are the install logs for the VCSA appliance located?
When upgrading from vCenter 6.0 to vCenter 6.5, what should be your first step?
What is the correct upgrade order to ensure a smooth upgrade?
Which performance counter is approximately the storage response time a guest OS will experience?
Which performance counter is the storage response time of the SAN?
What vSphere objects can the performance charts report on? (Choose two.)
Which performance counter is approximately the time the host takes to process a storage request?
What command will capture 100 sets of data in 5-second intervals?
See the accompanying image. What three options are most likely to resolve the issue reported? (Choose three.)
Which two technologies can report on physical switch settings? (Choose two.)
Which counter can indicate CPU contention?
Which counter can indicate significant guest impact due to memory contention?
Which counter indicates memory is being reclaimed?
What is the minimum licensing level required to enable High Availability?
What is the minimum licensing level required to enable the Distributed Resource Scheduler feature?
Which storage technologies are not affected by Ethernet network outages? (Choose two.)
Where can resxtop be run from by default?

Top Training Courses


 Training Course")


 Training Course")


 Training Course")


LIMITED OFFER: GET 30% Discount
This is ONE TIME OFFER

A confirmation link will be sent to this email address to verify your login. *We value your privacy. We will not rent or sell your email address.
Download Free Demo of VCE Exam Simulator
Experience Avanset VCE Exam Simulator for yourself.
Simply submit your e-mail address below to get started with our interactive software demo of your free trial.
